
Open Source AI Is Coming for Your Fine-Tuning Plays
(And Why Your NVIDIA Position Is Still Safe)

DeepSeek R1 just came for OpenAI's lunch money, and a lot of "AI-first" startups are about to get absolutely murdered.
RIP to Your "Fine-Tuned for X" Portfolio
If you're holding companies whose entire pitch is "we fine-tuned GPT-4 for [insert industry here]" and charging enterprise customers $15k/seat... I regret to inform you that your position is going to zero.
Rogo, Hebbia, and the whole gang of "we made RAG for your SaaS integrations" startups are about to learn a harsh lesson about moats in tech. When open source models are matching OpenAI's benchmarks while being literally free, good luck explaining to customers why they should keep paying premiums for marginally better prompt engineering. Look at Goldman’s CEO casually dropping that they can now automate 95% of an S-1 (IPO Prospectus) filing. Your “proprietary financial document processing” startup that raised at a $500M valuation? Yeah, about that…
Enduring Data Moats (aka: Why You're Probably Being Lied To)
Reality check: Most "data moats" are just glorified CSV files.
If your data can be replicated by a summer intern with Python and a Selenium script, it's not a moat
If your data is public information repackaged nicely, it's not a moat
If your data advantage can be neutralized or stolen by throwing more parameters at the problem, it's not a moat
Real data moats? They're rare and usually boring, because it’s hard to scale trust:
Enterprise workflows with decades of technical debt that requires too much knowledge transfer to be worth replacing, like Salesforce
Custom integrations for real patient data at scale, like Epic. If a healthcare agent product is a drop-in form filler, they’re probably just as easy to replace
User preference data that actually matters (shoutout to FinBench Arena—they’re a fork of Chatbot Arena, backed by Hyperbolic and Cohere, getting real bankers to tell them which model they prefer—not overfitting to academic benchmarks)
Everything else is lies or cope. And that last one? That’s where the future lies. Everyone’s obsessed with MMLU scores and HumanEval, but the real alpha is in knowing what actual users prefer in the wild. It’s the difference between studying for a test and doing the job for your customers.
The Economics of Model Theft
But even the most ironclad moat has a weakness: models can be stolen. Not literally stolen like a vault heist, but stolen in essence. With a fraction of the resources, someone can replicate the functionality of your model by distilling its outputs or using public APIs for fine-tuning.
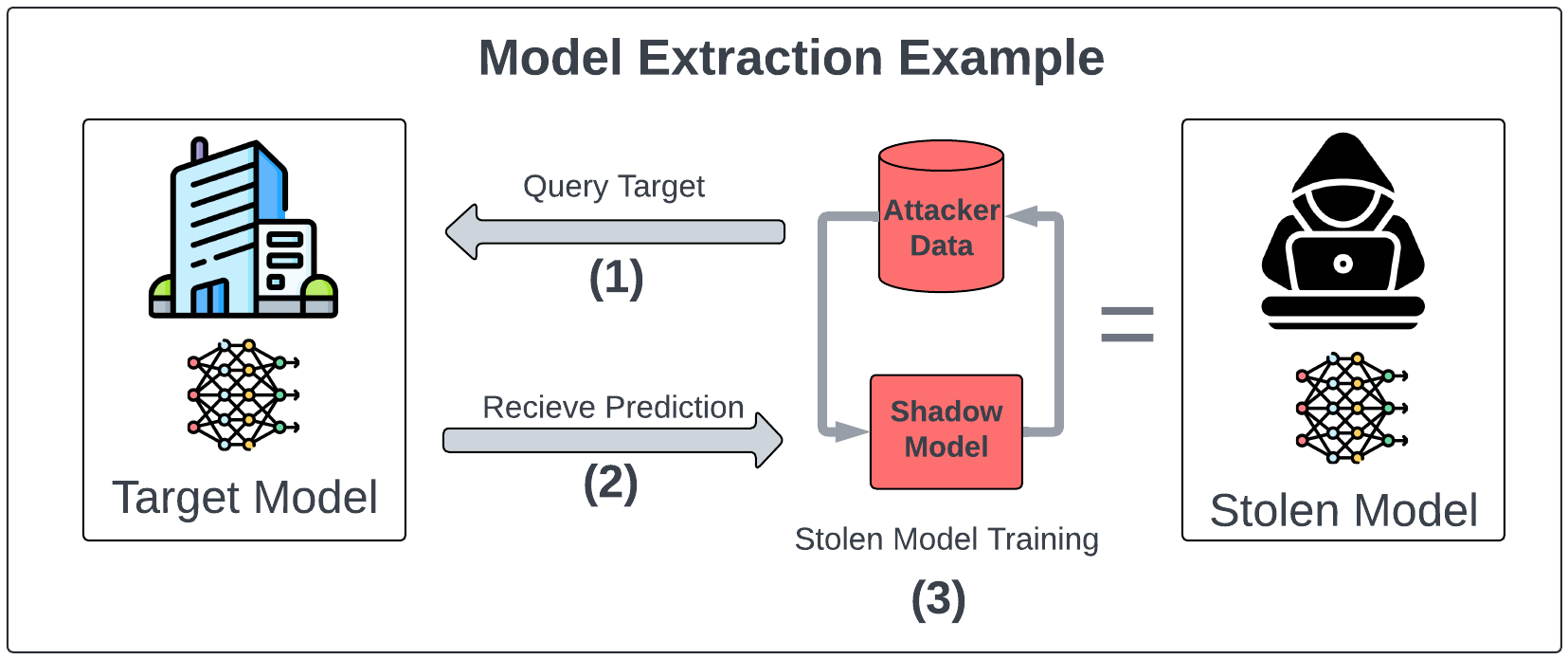
Model theft is the easiest shortcut to cutting-edge performance. OpenAI’s GPT-4 API isn’t just a tool for your chatbot startup—it’s a ready-made dataset for your competitor’s imitation model, as the Vicuna team from Berkeley demonstrated well before R1 dropped. A few thousand dollars in API calls, some clever prompt engineering, and voila: they’ve leapfrogged your R&D cycle.
Don’t Overreact
NVIDIA bulls can keep sleeping well at night, despite today’s dramatic crash. Why? Because even though reasoning is getting cheaper (it's literally just text + search with spicy math), we're nowhere near solving the actually hard problems in AI. Your RTX 4090 can help an LLM write Shakespeare, but good luck getting it to reliably pick up a cup without breaking it.
This is where Moravec's paradox comes in (sorry for the academic name-drop, but this one actually matters): The stuff humans find hard (like chess) is easy for AI, but the stuff toddlers find easy (like not falling over) is insanely compute-intensive. We're going to need a lot more chips before robots can fold laundry reliably. Firms like Fei-Fei Li’s World Labs will always have plenty of money to burn at your data center.
Might be time to have some uncomfortable conversations with your LPs.